
ChatGPT的智慧還不如貓狗?
2023/02/15
小柳建彥:對話式人工智慧(AI)正受到廣泛關注。在網站上向AI提問時,它會像真人寫的一樣用自然的語句做出回答。由於美國谷歌和微軟等大型科技企業參與相關競爭,這更吸引著全球熱切的目光。
 |
但是,直至目前公開的對話AI仍存在嚴重缺陷。雖然是由AI讀取大量數據,可以給出像模像樣的答案,但也存在很多致命性錯誤。很難説AI真正理解了問題和自己用於作答的詞彙的「含義」。
通過梳理「ChatGPT」等對話AI出現的諸多錯誤,就可以發現機器要達到真正的智慧所面臨的核心技術課題。
「老師」和「親媽」將展開競爭
由於2022年秋季美國初創企業OpenAI免費公開的ChatGPT在全世界引發熱議,此前一直不打算向公眾公開對話AI的谷歌改變了方針。
2月6日,谷歌首席執行官(CEO)桑德爾·皮查伊親自在官方部落格上宣佈,未來幾週內將在搜索服務中嵌入名為「Bard」的對話AI並投入使用。
 |
| 谷歌CEO桑德爾·皮查伊宣稱AI是谷歌最重要的技術領域(2022年10月,東京都澀谷區) |
據稱,在搜索欄中輸入提問內容後,會顯示用自然流暢的語句給出的答案,以及回答問題時作為依據所參考的網頁連結。
事實上,領先一步的ChatGPT的基礎是基於AI的大型語言模型,該模型建立在谷歌開發的被稱為「Transformer」的技術之上。不僅如此,谷歌還擁有數據量和能夠生成的句子類型數量遠多於OpenAI的模型。對於OpenAI來説,谷歌公開對話AI,就好比「老師」突然變成了競爭對手。
在「老師」發佈消息之後,「親媽」也跟著行動起來。在谷歌宣佈公開對話AI的第二天(2月7日),OpenAI的大股東微軟也發佈消息稱,在搜索服務必應(Bing)中嵌入了基於OpenAI技術的對話功能。據稱,通過與搜索功能同時使用,可以根據最新資訊以自然流暢的語句做出回答,還能夠對長達好幾頁的文檔進行概括提煉。
不善於追逐最新資訊
谷歌和微軟都強調,通過同時使用搜索和生成自然語言的功能,可以根據網上的最新資訊生成語句。反過來説,對話AI此前一直不擅長追逐最新資訊。
ChatGPT等的大型語言模型,每次更新資訊內容時,都需要重新讀取數量龐大的文獻數據。因為很難頻繁更新,所以模型內保存的資訊大多比較舊。
比如,當詢問ChatGPT「洛杉磯湖人隊(Los Angeles Lakers)最近一場比賽的上場陣容」時,得到的回答是「我只具備2021年之前的知識,無法回答您的問題」。
谷歌和微軟的對話AI同時使用網路搜索,因此會在資訊的同步性和準確性方面取得巨大進步。儘管如此,谷歌在2月8日進行Bard的演示時,仍顯示出了錯誤資訊,説是美國航空航太局(NASA)的詹姆斯韋伯太空望遠鏡成功拍攝到了史上第一張太陽系外行星的照片。這一錯誤資訊隨後引發爭議。可見,資訊的準確性仍有不少課題需要解決。
缺乏常識和邏輯
除了上述的問題外,對話AI還存在根本性的課題。目前推出的對話AI基本上都很難説已經可以理解自己所使用的詞彙的概念、含義、事物或現象的因果關係等「邏輯」。正因為如此,才會反覆出現簡單的事實誤認。
例如,向ChatGPT詢問「哥哥和姐姐有什麼不同」時,得到的回答是「雖然兄弟姐妹關係因家庭結構和出生順序不同而存在差異,但哥哥通常比姐姐年齡大」。之所以給出這樣不知所以然的答案,是因為沒有「理解」哥哥、姐姐等詞語的概念、相互之間的關係、家庭構成等全局情況。
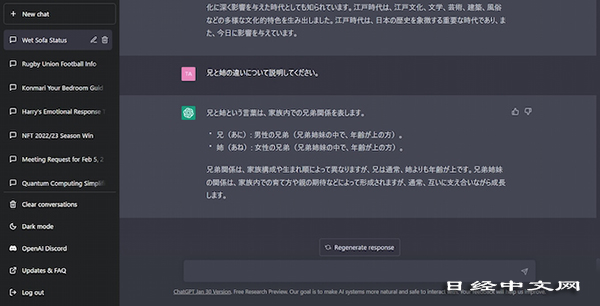 |
| 向ChatGPT詢問「哥哥」和「姐姐」的區別時,得到的回答含有錯誤內容 |
之所以會出現這樣的錯誤,是因為現在使用的絕大部分語言模型是機器學習型AI。因此,使用的語言基本上是單詞和短語的「排列」,機器通過讀入數量龐大的過去的文獻來識別排列類型。然後再計算出各類型出現的概率,尋找出接在問題之後的概率較高的字符串並加以顯示。
例如,在日語語言模型中輸入「我が輩(中文譯:我)」,使其生成後續的語句時,答案就會顯示在書籍、新聞報導、網站留言中出現概率最高的排列組合類型,即「は貓である(中文譯:是貓)」(見下圖)。ChatGPT還可以直接生成與「夏目漱石風格」的小説相類似的句子。
(編者注:《我が輩は貓である》是日本作家夏目漱石的長篇代表作,中文譯名為《我是貓》)
 |
| 語言模型是「學習」在基本單詞之後銜接什麼單詞的概率,並生成句子。(資料由NTT數據尖端技術提供) |
簡單計算也會出錯
也就是説,聊天AI不過是根據讀取數據找出概率高的詞序,並不是理解單詞、語句的「含義」以及家庭成員之間的關係等「常識」。因此,它不擅長回答那些不理解意義和常識就難以回答的問題。
由於不擅長邏輯,因此Chat GPT也不擅長簡單的計算。讓它做任意4位數之間的乘法,大都會算錯,並且反覆輸入相同算式時,總是給出錯誤的答案。
 |
| 讓ChatGPT計算4567×5678的乘法,會給出錯誤的答案。大規模語言模型不擅長世上文獻很少的小學生水準的數學。 |
也就是説,現有的聊天AI不適合用於調查事實。而應該僅限於在不管內容的真實性和準確性,只需要自動生成自然語句和軟體程式等文字列的目的時使用。
機器學習的極限和下一個AI
那麼,擁有與人類相當的「智慧」的AI的開發到底有沒有取得進展呢?熟悉日本國內外動向的日本科學技術振興機構研究開發戰略中心的研究員福島俊一表示:「具有邏輯思考、常識和認知的新一代AI的研究從幾年前就在推進」。
AI掀起過3次新技術浪潮。分別是1960年代、1980年代及從2010年代持續至今的第三次。其中,1960年代和1980年代是電腦根據人類預先編制好的邏輯,分析數據得出結論。由此也發現編制支援現實的無數邏輯不太可能,於是上一波浪潮在1990年代開始走向衰退。
2010年代開始、持續到現在的AI浪潮並不是人類思考邏輯,而是由讓電腦自己歸納出數據的各種類型的機器學習來引領。隨著相當於電腦大腦的半導體性能越來越高以及網際網路普及,可以收集全世界的數據,被稱為「深層學習」的可以識別複雜類型的軟體技術問世等要素全部得以實現。
如果將機器學習型AI和「大數據」結合起來,限定於特定用途,就可以完成人類不可能完成的工作。比如,通過讀取大量的面部照片,提高圖形識別能力,從而實現智慧手機開機時的面容解鎖。
 |
| Digital Garage董事伊藤穰一指出了依賴機器學習的AI的「極限」 |
不過,要實現自動駕駛及自律型多功能機器人,相當於頭腦的AI要具有識別眼前物體和周圍情況的能力,其中包括過去沒經歷過的情況。
這需要基於邏輯和常識的推論能力,僅靠依賴「過去」事例的機器學習型模型並不能順利實現。熟悉尖端技術動向的Digital Garage公司董事伊藤穰一指出:「谷歌、特斯拉及蘋果仍很難將自動駕駛汽車推向實用説明依靠機器學習的AI存在極限」。
「別説人類,就連貓狗的智慧都遠未達到」
對話型AI缺乏「常識」和「道理」也源於根據數據以歸納法方式探索相關類型的機器學習型AI的弱點。
兼具常識和邏輯思考的新一代AI如何才能實現?參考人類兒童自然掌握語言、空間認識及社會關係等的過程,讓電腦學習邏輯和常識的研究正以腦科學家和認知科學家也參與的跨學科途徑推進。另外,也有將在第2次AI浪潮下失敗的人類輸入邏輯和常識與尖端的深層學習相融合的嘗試。
關於通過機器實現與人類接近的智慧這一長期目標與現有AI技術的差距,開拓深層學習基本技術的美國Meta首席AI科學家、紐約大學教授Yann Lucan形容道:「目前先別説人類,就連貓狗的智慧都遠未達到」。
我們不能因為看到對話AI的流暢文章就誤以為AI智慧已經接近超越人類的「特異功能」(Singularity)。人類的科學技術在達到這一水準之前還需要實現眾多突破。
本文作者為日本經濟新聞(中文版:日經中文網)編輯委員 小柳建彥
版權聲明:日本經濟新聞社版權所有,未經授權不得轉載或部分複製,違者必究。