
會自學的最強阿爾法狗誕生 突破人類思維束縛
2017/10/19
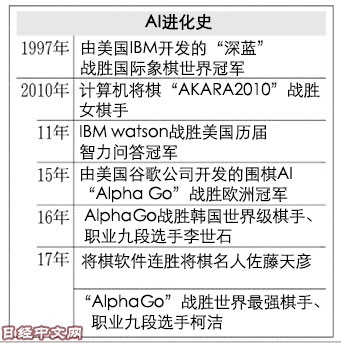
美國谷歌旗下的英國子公司沉思科技(DeepMind Technologies)日前開發出了新版本圍棋用人工智慧(AI)「AlphaGo Zero」。此前的AlphaGo在擊敗全球頂級棋手時通過學習約3千萬專業棋手的對弈數據使自身變得強大。但AlphaGo Zero無需人類作出示範,也能反覆與自己對弈,借助自學創造出勝率最高的下法。
以前的AlphaGo對人類就已經具有壓倒性優勢,棋力達到史上最強。這種實力有助於將來在産業方面得到應用,例如通過大量數據自動找到調整電力供需的時機等。
英國科學雜誌《自然》雜誌10月19日發表了相關文章。谷歌僅向AlphaGo Zero 教授了圍棋規則。AlphaGo Zero 將現有的2種學習方法結合起來,分別通過2種方法思考下一手,還能對彼此思考出的結果進行參照。
 |
| 柯潔與AlphaGo對弈(KYODO) |
AlphaGo Zero最初是隨機落子,但通過反覆與自己對弈,迅速提高水準。在進行實驗3天後,面對2016年3月擊敗頂級棋手李世石時的舊版AlphaGo取得了100戰全勝。
人類在多年的圍棋歷史中不斷自主完善了被稱為「定式」的慣用下法。在試驗40天後,AlphaGo Zero已經與自己對弈 2900萬局,強大程度超過2016年5月時面對全球最強棋手柯潔九段取得3連勝的AlphaGo版本。據稱,AlphaGo Zero還開始掌握人類未知的下法。
美國圍棋協會主席安迪·奧肯等在發給《自然》雜誌的稿件中指出,「AlphaGo Zero在中盤階段的若干判斷簡直就像迷一樣」。另一方面,隨著人工智慧和人類在下棋時總結出了相同的定式,證明「人類長達數個世紀的圍棋活動取得的成果並非全部錯誤」。
沉思科技的首席執行官傑米斯·哈薩比斯在AlphaGo擊敗最強人類棋手時表示,「這是最後一次和人類對弈」。為達成「完全不依賴人類的人工智慧」這個目標,哈薩比斯在此後繼續對AlphaGo進行了改進。
此前,人工智慧曾將人類的對弈數據作為「教師」加以學習。因此有觀點指出,人工智慧雖然強大,但僅僅處於人類知識的延長線上。沉思科技通過讓人工智慧從零開始自學,採用被稱為「沒有教師的學習」方式,創造出了不受人類思維束縛的革新性人工智慧。
 |
哈薩比斯表示,「人工智慧有可能推動人類的智力向前發展,給全人類帶來積極影響」。
沉思科技與英國國家醫療服務體系(NHS)展開合作,除了將人工智慧用於早期發現疑難雜症外,還將用於調整電力供需等方面。將來,還期待人工智慧在依靠人類力量難以解決的新材料開發、探究蛋白質生成機制等方面做出貢獻。
新技術將來還可能在産業方面做出貢獻。例如,從大量數據中發現人類難以意識到的提升效率的方式等。據悉,以各種用電數據為基礎,人工智慧將有助於節省電力。由於像AlphaGo Zero一樣的人工智慧可以「無師自通」,在宇宙和海洋等觀測數據不足的領域也有可能做出貢獻。
日本經濟新聞(中文版:日經中文網)川合智之 華盛頓
版權聲明:日本經濟新聞社版權所有,未經授權不得轉載或部分複製,違者必究。