ChatGPT的智慧還不如貓狗?
2023/02/15

比如,當詢問ChatGPT「洛杉磯湖人隊(Los Angeles Lakers)最近一場比賽的上場陣容」時,得到的回答是「我只具備2021年之前的知識,無法回答您的問題」。
谷歌和微軟的對話AI同時使用網路搜索,因此會在資訊的同步性和準確性方面取得巨大進步。儘管如此,谷歌在2月8日進行Bard的演示時,仍顯示出了錯誤資訊,説是美國航空航太局(NASA)的詹姆斯韋伯太空望遠鏡成功拍攝到了史上第一張太陽系外行星的照片。這一錯誤資訊隨後引發爭議。可見,資訊的準確性仍有不少課題需要解決。
缺乏常識和邏輯
除了上述的問題外,對話AI還存在根本性的課題。目前推出的對話AI基本上都很難説已經可以理解自己所使用的詞彙的概念、含義、事物或現象的因果關係等「邏輯」。正因為如此,才會反覆出現簡單的事實誤認。
例如,向ChatGPT詢問「哥哥和姐姐有什麼不同」時,得到的回答是「雖然兄弟姐妹關係因家庭結構和出生順序不同而存在差異,但哥哥通常比姐姐年齡大」。之所以給出這樣不知所以然的答案,是因為沒有「理解」哥哥、姐姐等詞語的概念、相互之間的關係、家庭構成等全局情況。
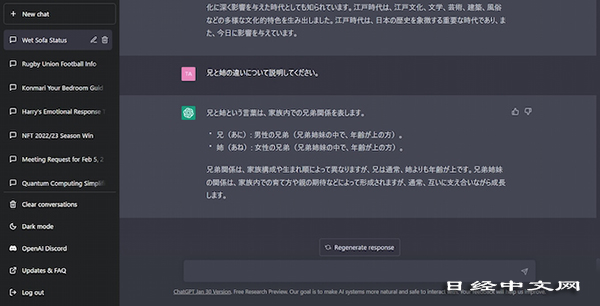 |
| 向ChatGPT詢問「哥哥」和「姐姐」的區別時,得到的回答含有錯誤內容 |
之所以會出現這樣的錯誤,是因為現在使用的絕大部分語言模型是機器學習型AI。因此,使用的語言基本上是單詞和短語的「排列」,機器通過讀入數量龐大的過去的文獻來識別排列類型。然後再計算出各類型出現的概率,尋找出接在問題之後的概率較高的字符串並加以顯示。
例如,在日語語言模型中輸入「我が輩(中文譯:我)」,使其生成後續的語句時,答案就會顯示在書籍、新聞報導、網站留言中出現概率最高的排列組合類型,即「は貓である(中文譯:是貓)」(見下圖)。ChatGPT還可以直接生成與「夏目漱石風格」的小説相類似的句子。
(編者注:《我が輩は貓である》是日本作家夏目漱石的長篇代表作,中文譯名為《我是貓》)
 |
| 語言模型是「學習」在基本單詞之後銜接什麼單詞的概率,並生成句子。(資料由NTT數據尖端技術提供) |
簡單計算也會出錯
也就是説,聊天AI不過是根據讀取數據找出概率高的詞序,並不是理解單詞、語句的「含義」以及家庭成員之間的關係等「常識」。因此,它不擅長回答那些不理解意義和常識就難以回答的問題。
版權聲明:日本經濟新聞社版權所有,未經授權不得轉載或部分複製,違者必究。
報道評論
- 日經中文網公眾平臺上線!






HotNews
金融市場
| 日經225指數 | 57639.84 | -10.70 | 02/12 | close |
| 日經亞洲300i | 2697.45 | 10.64 | 02/12 | close |
| 美元/日元 | 153.29 | -2.27 | 02/12 | 21:09 |
| 美元/人民元 | 6.9001 | -0.0122 | 02/12 | 10:34 |
| 道瓊斯指數 | 50121.40 | -66.74 | 02/11 | close |
| 富時100 | 10491.110 | 19.000 | 02/12 | 11:59 |
| 上海綜合 | 4134.0178 | 2.0329 | 02/12 | close |
| 恒生指數 | 27032.54 | -233.84 | 02/12 | close |
| 紐約黃金 | 5071.6 | 67.8 | 02/11 | close |